
Païou : Mandriva Linux depuis 2002. Aujourd'hui, c'est Mageia Linux
On se lasse de tout, sauf de comprendre.
Attribué à Virgile.
14 juillet 2010 : Ébauche de cette page, toujours encore en construction.
12 juillet 2011 : Nouvelle présentation.
C'est : plutôt un peu ardu. Mais, sans essayer de comprendre toutes les techniques, vous pouvez apprécier la multitude de techniques.
Les fichiers de texte sont compressés, les images sont compressées, les données audio sont compressées, les vidéos sont compressées ...
Païou se demande un peu comment cela fonctionne, puisque cette notion de compression apparaît dans plusieurs pages du site.
Ma page essaie de résumer le très bon article de Wikipédia : 

Dans la théorie de l'information, l'entropie de Shannon quantifie l'information contenue dans un message.
Il suffit de retenir que, plus un message est redondant, moins il contient d'information et plus son entropie est petite.
Les algorithmes de compactage visent un même objectif : éliminer de la redondance et donc augmenter l'entropie, c'est à dire transmettre exactement la même information, mais avec moins d'octets.
Le compactage ne tient pas compte de la nature des données. Il est utilisé pour toutes sortes de fichiers binaires (texte, images, fax ...). Au décompactage, les données sont restituées sans pertes.
Une notion interviendra dans plusieurs des codages : prefix code : le code d'un élément est toujours différent du début (préfixe) du code d'un autre élément. Ainsi, il n'est pas nécessaire de prévoir un séparateur entre deux codes qui se suivent et dont on ne connait pas la longueur.
Différentes techniques sont utilisées et certains codages utilisent simultanément plusieurs techniques afin d'arriver à un résultat optimal.
Le compactage RLE (Run-length encoding) : Quand il y a une succession de n éléments identiques (octets), il faut moins d'espace pour écrire qu'il y a n éléments que d'écrire n fois le même élément.
Ici, il faut un caractère spécial qui indique que ce qui suit est d'abord le nombre de répétitions et ensuite seulement le code du symbole.
Il est utilisé par le fax et par de nombreux formats d'images (BMP, PCX, certains TIFF).
Il est également dénommé codage VLC (variable length code) car la longueur du code résultant est variable :
L'Entropy encoding consiste, habituellement, à créer un prefix code et à l'assigner à chaque nouveau symbole (octet, par exemple) qui se produit à l'entrée. Ce code est de longueur variable, les codes les plus courts étant attribués aux symboles les plus fréquents (contrairement au code ASCII qui a une longueur fixe).
Différents algorithmes correspondent à cette technique : Huffman, Adaptive Huffman, arithmétique (Shannon-Fano, Range)
Lempel-Ziv (LZ77 LZ78), Lempel-Ziv-Welch (LZW)
Les codages par dictionnaire se basent également sur l'analyse des répétitions dans les données à traiter. Cependant, on recherche ici des occurrences de motifs de longueur plus importante que celle d'un octet.
Les motifs répétés prennent place dans un dictionnaire, et chacun d'eux est remplacé, dans les données compactées, par sa seule adresse dans le dictionnaire. L'algorithme travaille ainsi en une seule passe.
Dans le codage par prédiction la valeur de chaque symbole est prédite à partir des symboles précédemment codés. Seul l’écart entre la valeur prédite et la valeur réelle est quantifié puis codé et transmis. L’écart étant en général faible, sa représentation nécessite moins de bits que le symbole lui même.
Pour plus d'informations sur ces compactages et compressions, voyez les pages de Wikipedia (le plus souvent en anglais). Elles ont grandement servi à la confection de ce chapitre.
Il est un fait connu qu'un algorithme de compression sans pertes ne peut pas traiter tous les signaux possibles, de sorte que la plupart des compresseurs se limitent à un domaine donné et essaient de travailler aussi bien que possible dans ce domaine. La compression audio n'échappe pas à cette règle.
Le domaine de la compression audio se subdivise lui-même en plusieurs sous-domaines :
Nous verrons que les techniques de compactage vues précédemment sont utilisables pour la compression audio. Cependant, la compression audio présente quelques spécificités :
Des techniques plus spécifiques sont plus adaptées. Très souvent, les codecs (logiciels de codage et de décodage des sons) associent plusieurs de ces techniques.
Au lieu de coder la valeur de chaque échantillon, on code la valeur de la différence entre l'échantillon actuel et le précédent.
Cette différence est plus petite et on gagne ainsi en volume à stocker ou transmettre. Inconvénient : les erreurs de quantification s'ajoutent.
Pour obtenir une meilleure précision, on utilise plusieurs échantillons précédents pour prédire la valeur du nouvel échantillon.
Les échantillons précédents sont pondérés par des coefficients prédictifs. Cette technique permet de coder sur 6 bits au lieu de 12 ou 16 avec PCM.
Le principe : faire varier le nombre de bits utilisés pour coder le résidu (faible variation = petit nombre de bits).
Cette méthode est utilisée pour les normes ITU-T G.721 et ITU-T G.722
La compression repose sur des modèles psycho-acoustiques qui décrivent le comportement subjectif de l'oreille humaine en fonction de la fréquence, du volume et du temps.
Bandes : notre oreille ne perçoit pas toutes les fréquences de la même façon. Pour l'oreille, l'échelle des fréquences n'est pas continue, mais découpée en vingt-quatre bandes critiques. Ces bandes de fréquences, liées à des zones sensibles bien précises de l'oreille interne, lui permettent d'être très sélective. Ainsi, nous différencions plus aisément les sons graves ou moyens que les aigus. Cela s'explique par le fait qu'il est beaucoup plus facile de distinguer deux sons s'ils appartiennent à des bandes différentes.
Masquage : tout son fort peut en cacher un autre plus faible; c'est ce que l'on appelle le masquage simultané. Il serait donc absurde, lors d'une compression de garder les informations qui seront masquées.
Notons que le masquage joue aussi dans le temps : bien que l'influence d'un son fort sur un plus ténu qui le précède (pré-masquage) soit très courte avec 20 ms au maximum, le même son fort peut continuer à en "écraser" un autre entre 100 ms et 200 ms après avoir été coupé (post-masquage).
Ainsi, il est possible d'éliminer des signaux qui ne sont pas perçus par l'oreille, soit parce qu'ils sont masqués par un autre son, soit parce que l'oreille est peu sensible à cette fréquence.
En stéréo, il y a une certaine similitude entre les signaux des deux canaux. C'est également le cas lorsqu'il y a encore plus de canaux (5.1 ou 7.1)
Ceci peut être exploité pour réduire le volume du signal binaire.
L'oreille ne perçoit pas toutes les fréquences de la même façon.
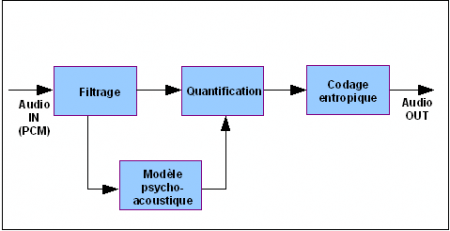
Le signal audio va être décomposé en plusieurs bandes de fréquences et chaque bande va être traitée différemment.
Pour chaque bande on va supprimer l'information inutile. Il y a donc perte d'information par rapport au signal original, mais lorsque le codage est bien fait, l'oreille ne perçoit pas de différence.
Il faut réaliser une analyse en temps réel de la distribution amplitude/fréquence. Pour ceci :
Le codage par synthèse est très différent du codage différentiel. L'idée n'est plus de manipuler les échantillons pour éliminer la redondance et les corrélations entre échantillons, mais au contraire de considérer des blocs d'échantillons et de construire un modèle qui produise des échantillons statistiquement identiques (ou proches) des échantillons originaux. Ce modèle donc permet de synthétiser des échantillons avec des propriétés statistiques données, d'où le nom de codage par synthèse.
Le signal est analysé et traité avant d'être codé. Ce codage est très utilisé dans le traitement des sons et également dans la synthèse vocale
Le codage LPC admet, comme hypothèse, que le son (parole) peut être représenté par une vibration émise au bout d'un tube avec, éventuellement, un ajout de sifflements (consonnes sifflantes) ou de petits bruits secs (consonnes occlusives). Bien que cela semble un peu grossier, ce modèle est en fait une approximation de la réalité de la production de la parole.
La glotte (l'espace entre les cordes vocales) produit la vibration, caractérisée par son intensité (volume) et sa fréquence (hauteur). Le conduit vocal (la gorge et la bouche) forme le tube, qui se caractérise par ses volumes de résonance (ouverture de la bouche, position de la langue, ouverture ou fermeture du conduit vocal). Ces volumes donnent naissance aux formants (pics de résonnances) du son produit.
En première approximation, les voyelles sont caractérisées par deux formants pour chacune. Les sons sifflants ou bloquants sont générés par l'action de la langue, des lèvres et de la gorge.
Le codage LPC (Linear Predictive Coding) consiste donc à synthétiser des échantillons à partir :
En pratique, on modélise ce système par un ensemble de cylindres de diamètres différents. Le choix de la fonction d'excitation (sinusoïde ou bruit blanc) dépend des caractéristiques, voisée ou non voisée, du signal. Un signal voisé correspond à une voyelle. Un signal non voisé correspond à une consonne.
Le processus de synthèse a donc deux phases, qui sont :
Chaque phase est exécutée toutes les 20 ms. Les valeurs qui décrivent l'intensité et la fréquence de la vibration et le reste du signal, peuvent être stockées ou transmises ailleurs. À la réception, le signal vocal peut être restitué à partir de ces données.
Le CELP (Code Excited Linear Predictive) est une extension du codage LPC. Il comporte toujours deux phases, correspondant aux fonctions d'excitation et de transfert. L'identification de la fonction de transfert est identique à celle faite avec LPC. Par contre, la fonction d'excitation n'est pas seulement un bruit blanc ou un sinusoïde, mais une combinaison linéaire de fonctions stochastique (c'est à dire de bruit) et périodiques.
L'identification de ces fonctions est très coûteuse en temps CPU (et d'ailleurs le codeurs CELP sont en général implémentés avec l'aide de cartes spécifiques de traitement de signal), mais la qualité obtenu est bien meilleure qu'avec le codeur LPC.
Le codage GSM utilise une variante du codeur CELP appelée RPE (Regular Pulse Excited), car la fonction d'excitation fait intervenir des impulsions périodiques couplées à une boucle de prédiction à long terme. Les détails de l'algorithme sont complexes. On obtient alors un codage de qualité très proche de PCM, mais avec un débit de seulement 13 kb/s.
La transformation de Fourier est connue pour le traitement des signaux analogiques. Ceci est son adaptation aux signaux numériques.
En compression du son ou de l'image, des transformées proches de la TFD sont appliquées en général sur des portions de signal, pour réduire la complexité.
La FFT (Fast Fourier Transform ou transformée de Fourier rapide) est ici utilisé après échantillonnage du signal d'entrée basses fréquences (audio). Avantage : il est capable de capturer les signaux en temps réel avec une résolution spectrale très fine
CELT (repris maintenant dans le projet Opus) est un codec open-source, vocal, utilisable pour des applications à très faible retard, telles que VoIP (voix sur IP). CELT est un transform codec, basé sur Modified Discrete Cosine Transform (MDCT). Support de la voix et de la musique, de la stéréo, Bande passante audio 44,1 kHz et 48 kHz, latence 3 à 9 ms, voix et musique, stéréo.
La transformée en cosinus discrète ou TCD (de l'anglais : DCT ou Discrete Cosine Transform) est une transformation proche de la transformée de Fourier discrète (DFT).
La compression audio se fait souvent en plusieurs phases
Exemple :
Un autre exemple :

Quand on parle image, il faut se souvenir qu'il y a deux sortes :
